LTO != PGO
Ballooning your build times for fun and profit.
PGO is just LTO with extra profiling data, right?
Wrong! December, 2025: hot off my last dev talk of the year, I get asked this question by one of the leads at Feral. I’ve been talking about link-time optimisation (LTO), a nice, easy, one-and-done topic that (little do I know it yet) will end up rattling around the back of my head for the rest of the festive period. That’s because my colleague has made me realise, I’ve given a whole presentation on how linking unlocks extra optimisations a compiler can’t make on a per-unit basis - and completely failed to explain what those extra optimisations actually are.
Please consider this my mea culpa, a spiritual sequel to my post on profile-guided optimisation. PGO, LTO, plus a third, much larger project of mine I’m not quite ready to share just yet, are conceptually very similar. I like to think of them as cheat codes for CPU optimisation; less the ABCs than the ↑↑↓↓←→←→BAs of performance engineering. They’re cheating because, well, they’re glorified compiler flags, and I strongly suspect what stops devs from using them is simply not knowing they exist.
But plenty of digital ink - pixels? - have already been spilled on LTO (J. Ryan Stinnett’s being my personal favourite of the many very accessible introductions available). Much like I did with PGO, what I want to do here is just walk through my own personal experience integrating the process into a build pipeline, and make explicit some subtler points I’ve had to read between the lines elsewhere. It’ll be a bit circuitous, but by the end of this article I should have convinced you of what the Os in LTO (and PGO) are really doing, the way my colleague and I convinced ourselves. Some code snippets and console commands will be specific to my compiler of choice, but there should be enough here to be relevant whatever your setup.
But what is a Linker?
Looking at a C++ developer’s toolchain, it’s easy to get hung up on the compiler. It is where the magic (read: optimisation) happens. But compilers alone do not a toolchain make, they rely on linkers and other ancillary programs:
 The toolchain transforms source code to (executable) machine code. The preprocessor, compiler, and assembler are, technically, their own programs, but I’ll lump them together and call them the compiler for convenience; they aren’t the part of the toolchain we’re interested in today.
The toolchain transforms source code to (executable) machine code. The preprocessor, compiler, and assembler are, technically, their own programs, but I’ll lump them together and call them the compiler for convenience; they aren’t the part of the toolchain we’re interested in today.
Toolchains think about a project in terms of compilation units, which in C++ will be .cpp source files. At compile time, sources get lowered, unit by unit, into independent machine code binaries native to your desired instruction set (x86, ARM, etc.). The linker is what then takes these native object files (.o) and merges them together. Whether returning an executable (.exe) or maybe a library (.dll), this last step is machine code in, machine code out.
Now, when we talk about linking object files, we’re linking them by their symbols. These are any named entities in a program that get attached to a fixed memory location - e.g. functions and class methods, global and static variables - many of which will be externally visible beyond the scope of their own compilation unit. When externals are referenced elsewhere it’s the linker that matches them to their definitions, a process known as symbol resolution.
While they will attempt some amount of dead code stripping, compilers evaluate each unit in isolation. Only at link time, with a global view of the executable, can we spot unused externals and remove them. Linkers are also responsible for resolving relocations using newly-finalised runtime memory addresses, but I’ll refer you to Miguel Young for the further reading there. Crucially, compile-time optimisations run in parallel, whereas we only unlock these further ‘whole program’ capabilities by linking on a single thread.
LLVM, Revisited
If you read PGO, But Better, you might remember I introduced Clang as my go-to compiler, the one I’ll be writing these blogs about. You might also remember that it’s the C/C++ frontend of the LLVM compiler infrastructure, needed to translate source code into an intermediate representation (IR) on which the middle-end performs a series of language-agnostic passes. And if you remember that after optimisation, the backend translates the IR again, it’s no great shock that this is where we return a bunch of instruction set-specific object files, ready for linking.
For a blog about link-time optimisations (we’re getting there, I promise) what may come as a surprise is our choice of linker barely matters. LLVM’s lld-link writes executables in the Common Object File Format COFF, a binary file format that runs on Windows, ld.ldd the Executable and Linkable ELF Format targeting Linux/Android, and ld64.ldd the Mach-O Mach Objects for macOS/iOS. Any such flavour of the LLD subproject - and for that matter, any of the respective system linkers they were designed to replace - will slot into the LLVM toolchain as below:
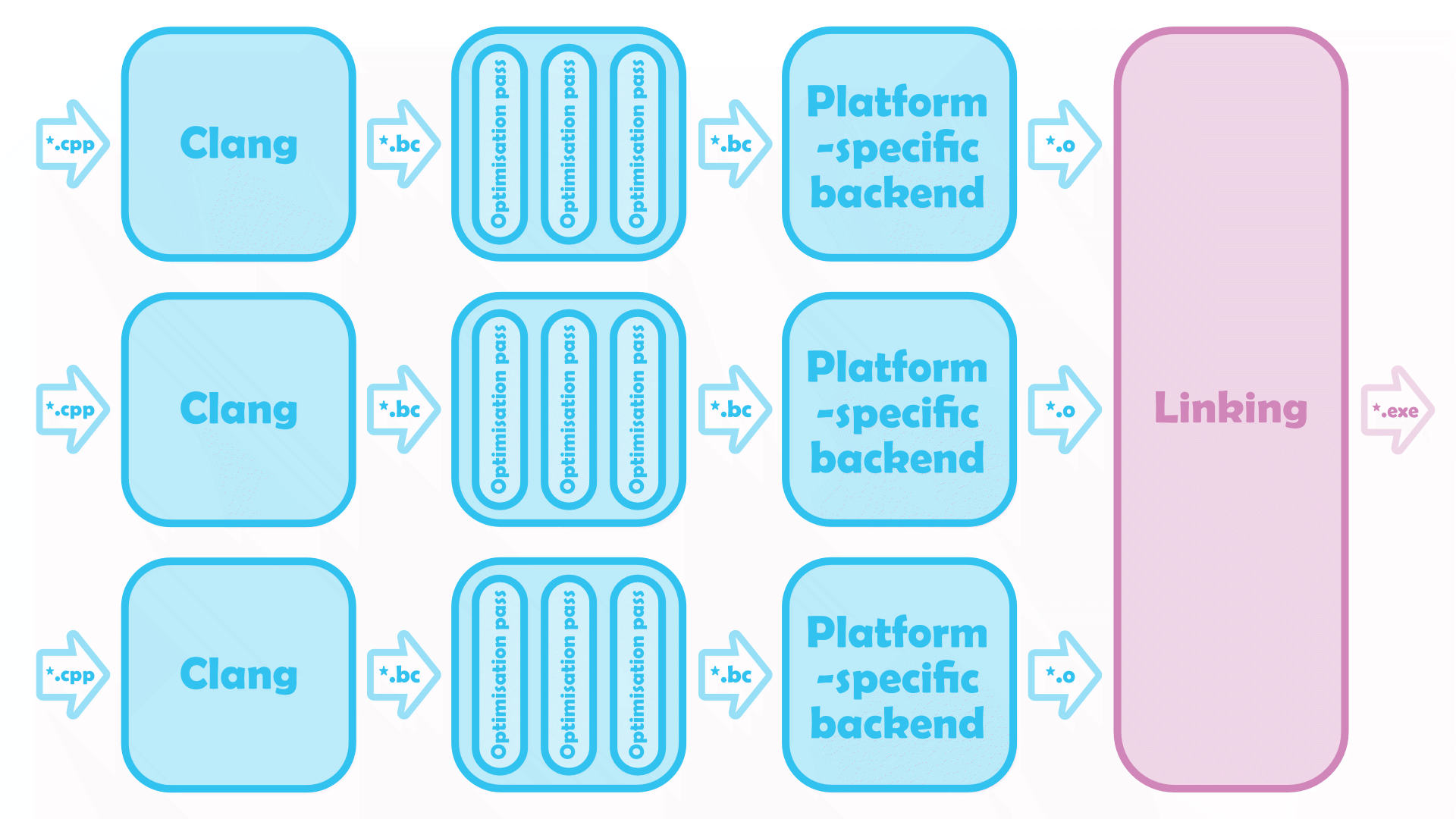 No LTO LLVM’s default build pipeline. Sources are compiled in parallel, then linked into a final executable… but what are those
No LTO LLVM’s default build pipeline. Sources are compiled in parallel, then linked into a final executable… but what are those *.bc files?
LLVM IR
Intermediate representations are abstractions of source code, used to write easily retargetable compilers. Let’s say you’re a compiler engineer, and you want to lower any of $n$ source languages to any of $m$ instruction sets. Rather than building $n \times m$ compilation pipelines start to finish, with a set of optimisation passes mapping IR to IR you’ll only need a single, language- and machine-agnostic middle-end. Once this transformation step is squared away, the $n$ frontends and $m$ backends it’ll then take to translate to and from IR can be written independently of one another, your workload increasing with $\mathcal{O}(n+m)$ instead of $\mathcal{O}(n \times m)$ as you extend the compiler further.
Beyond this raison d’être, the LLVM IR tries to complement its surrounding compiler infrastructure. While it is not uncommon for a compiler to use several different IRs to get from source code to native machine code, the LLVM middle-end is designed for modularity and therefore uses the same IR at every pass. Granted, the syntax of LLVM IR is already more legible than assembly (let alone other IRs!), but as Adrian Sampson points out, it certainly can’t hurt that the curious programmer playing about with optimisation passes only needs one language throughout. The compiler processes this in its binary form (.bc), often referred to LLVM bitcode, but it can also be disassembled to an equivalent human-readable textual form (.ll) by llvm-dis (and reassembled with llvm-as).
LLVM bitcode can be conceptualised as machine code for a virtual machine: there isn’t a physical computer architecture that’ll run these binaries, but LLVM pretends there is in order to standardise its optimisations. With this understanding, we can broaden our earlier definition of an object file to include any file that contains machine code, virtual or native. .bc files are the virtual versions of .os, much like .lls read as quote-unquote virtual assembly. When compiling with clang -S or clang -c, adding an extra -emit-llvm flag will indeed return the IR analogue of the desired assembler or object file, respectively.
Consider how a trivial C++ function translates to IR:
1
2
3
4
5
static int qux()
{
baz();
return 10;
}
1
2
3
4
define internal i32 @qux() {
call void @baz()
ret i32 10
}
In both languages, we define @qux, a function internal to the source file (rather than an external symbol). @qux in turn calls @baz, some other void function, before returning a value of 10 itself. Really, the only difference with C++ is how we denote types. Integer types are denoted iN, and floating-point types fN, such that int becomes i32, double becomes f64, and so on. In fact, because IR is only an abstract representation of an instruction set, it doesn’t need to worry about physically storing variables in a fixed number of bytes. That means N can be any natural number, not strictly a multiple of eight - notably, Booleans are written i1 in IR!
So far, so good, yeah? Let’s go ahead and borrow a bigger chunk of code from the LLVM docs…
1
2
3
extern int foo();
extern void bar();
extern void baz();
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include "foobar.h"
static int qux();
static int i = 24;
int foo()
{
int data = 0;
if (i < 0)
{
data = qux();
}
data = data + 42;
return data;
}
void bar()
{
i = -1;
}
int qux()
{
baz();
return 10;
}
clang foobar.cpp -emit-llvm -S returns foobar.ll as the ‘assembled’ textual form of IR (minus some metadata, removed for clarity):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
@i = internal global i32 24
define i32 @foo() {
%1 = alloca i32
store i32 0, ptr %1
%2 = load i32, ptr @i
%3 = icmp slt i32 %2, 0
br i1 %3, label %qux, label %add42
qux:
%4 = call i32 @qux()
store i32 %4, ptr %1
br label %add42
add42:
%5 = load i32, ptr %1
%6 = add nsw i32 %5, 42
store i32 %6, ptr %1
%7 = load i32, ptr %1
ret i32 %7
}
define void @bar() {
store i32 -1, ptr @i
ret void
}
declare void @baz()
define internal i32 @qux() {
call void @baz()
ret i32 10
}
There are plenty of @s here, and plenty more %s. These are the sigils LLVM prepends to user-defined symbols to indicate their scope. We’ve seen @ is the prefix used for functions, but it also marks out global variables like @i. %s, on the other hand, are used for local registers holding top-level variables that get set exactly once. If that’s true of all variables in an intermediate representation, we say it’s in static single assignment form (SSA), an incredibly valuable property for compiler design (to find out why, Miguel Young is once again yer man).
Canny readers will already be wondering, how is it legal to store i32 0, ptr %1 in an SSA? And here’s the neat thing - it’s not! The LLVM IR allows address-taken variables to be allocated, stored and loaded at will. It allows these, even though they unapologetically break SSA form; the compiler can no longer know “which variables are defined and/or used at each statement.”
As a compromise, address-taken variables can only be accessed indirectly through top-level variables, using, e.g., the ptr dialect. ptr @i and ptr %1 are mutable integers, but the pointers stored at @i and %1 will not change. That makes LLVM IR a partial SSA. It is reasonable, I think, that most blogs gloss over this distinction, but it’s the detail I needed to make the syntax click. Trying to satisfy myself store could exist in a true SSA was shunting a square peg into a round hole.
Another important feature of the IR is the control flow by which a program executes instructions - but before we get to that, I’ll let you in on a dirty secret. Your CPU has a fetish. Your CPU has a fetish, specifically, for running code in order, and basic blocks are the maximal units of code for which this is actually possible. Each one consists of some sequence of instructions executed top to bottom as written on the page, its last a singular terminator redirecting the control flow to another block.
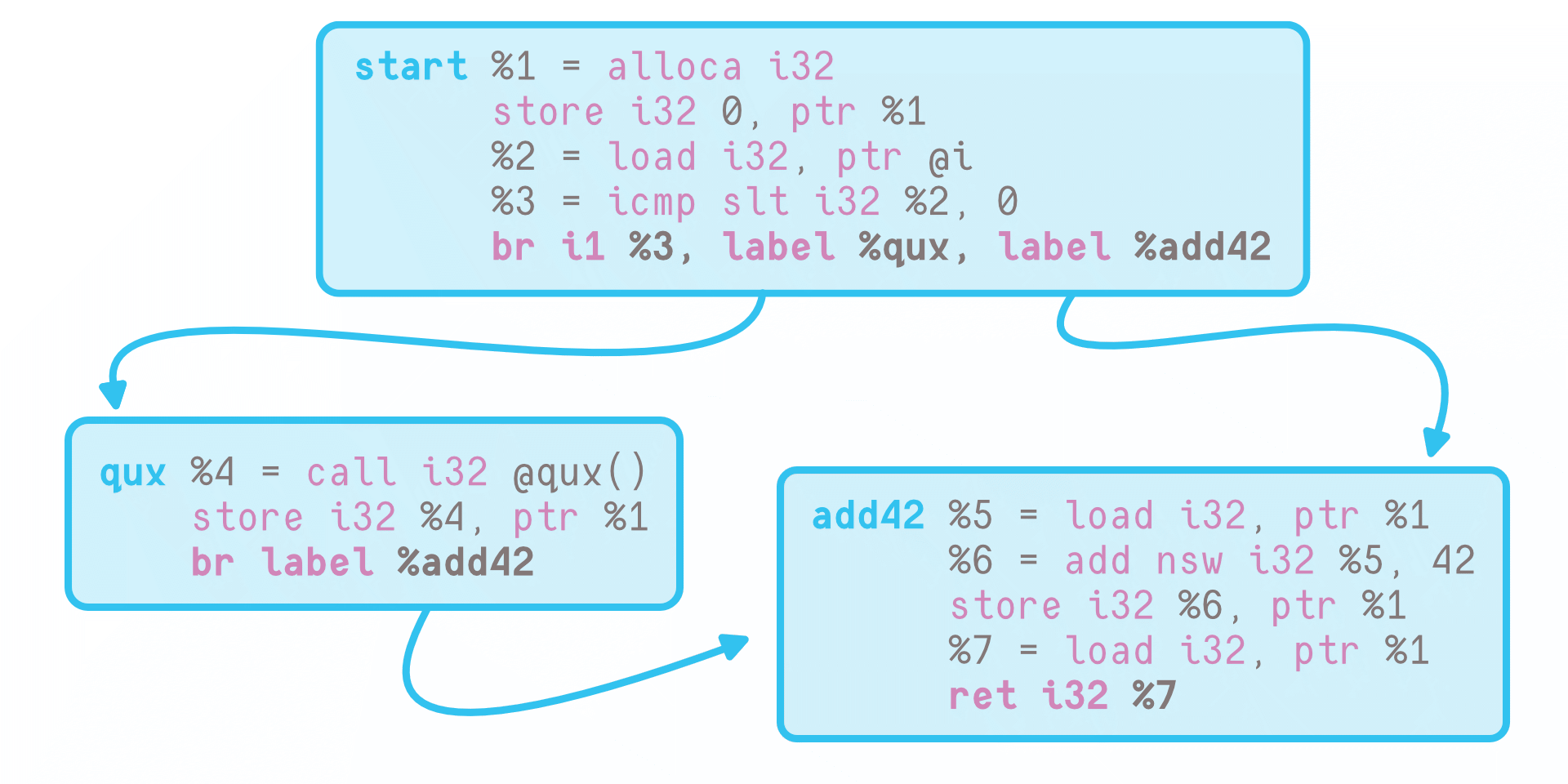 Control Flow Graphs
Control Flow Graphs @foo has three blocks: the start of the function (denoted %0 in LLVM IR), %qux, and %add42. These form a CFG.
Branches, function calls, etc., are the (directed) edges that connect basic blocks into a control flow graph (CFG), which LLVM encodes with its terminator instructions. ret we’ve already discussed, that counts as a terminator because it returns us to wherever we came from on the stack. br, meanwhile, signifies branching. br i1 %3, label %qux, label %add42 is a bog-standard if/else statement. It might be more surprising to know br also has an unconditional form: br label %add42 always takes us to block %add42,
Incidentally, basic blocks help make sense of what’s going on with int data. It is, I’m sure, quite strange that a local variable we never take the address of nevertheless needs stored as an address-taken variable in @foo. Now, we see that if %0 instead initialised %1 = 0 and %qux still set %4 = call i32 @qux(), %add42 would have no way of knowing which register to add nsw i32 with 42!
There’s one last bit of syntax in the LLVM LangRef I’d like to talk about, but you won’t find it in the example above. Luckily, we can recompile foobar.cpp with an extra -O2 flag to tease it out…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@i = internal global i1 false
define i32 @foo() {
%1 = load i1, ptr @i
br i1 %1, label %qux, label %add42
qux:
tail call void @baz()
br label %3
add42:
%2 = phi i32 [ 42, %0 ], [ 52, %qux ]
ret i32 %2
}
define void @bar() {
store i1 true, ptr @i
ret void
}
declare void @baz()
Already, @qux has been inlined, @i safely simplified to a Boolean, and several registers removed. However, where I really want to draw your attention is the phi node (Φ) added in line 12. This functions like a switch statement, conditioned on the predecessor block in the control flow. %2 is set to 42 if we’ve jumped directly from line 5 into %add42, but 52 should we be routed through %qux first. A basic block might have any number of phi nodes, but they must always be grouped together at the top of their chunk of code (i.e. before a single non-phi instruction is called).
Because they only link a basic block’s registers to their predecessors, phi nodes are better thought of as called along the edges of a CFG than within the blocks themselves.1 They are fake operations, in a very technical sense. Kenneth Zadeck, who along with Barry Rosen and Mark Wegman proposed SSA in 1988, all but admits to choosing the name Φ because it was more publishable than saying “phony functions” outright. I’ve even seen some sources transliterate Φ as the Greek letter for phony - but that part’s a false etymology, they’re just soundalikes. Ironic.
1 This formalism is completely equivalent to the block arguments preferred by more modern IRs.
Link-Time Optimisations (LTO)
Congratulations, you’ve now read your first IR! If you’re not a compiler engineer, I grant you it’s probably not a language you’ll ever need to be fluent in. Nevertheless, it has its niche in your programmer’s toolbox, worth picking out and dusting off every now and then to see how an extra flag is changing your code.
But this is still a blog about LTO; we need a second source with which to link.
1
2
3
4
5
6
7
8
9
10
11
12
#include "foobar.h"
#include <stdio.h>
int main()
{
return foo();
}
void baz()
{
printf("Hello world!\n");
}
Here, we can expect the linker to recognise bar as an unused external and strip it accordingly. However, it won’t perform constant propagation to determine that i is never changed, that %qux and therefore @baz become unreachable, that main will never not return a value of 42. While symbol resolution, dead code stripping, etc., are, technically speaking, optimisations performed at link-time, we’ll distinguish LTO from any inferences that can be made by the linker alone.
Instead, let link-time optimisation (LTO) be the process of applying across multiple sources the same optimisations the compiler applies to each source. In LLVM specifically, this extra work will be dispatched to libLTO, a shared object that exists in dialogue with the linker, acting as a wrapper for the LLVM middle-end. The following flavours of LTO are all variations on a theme: running the compiler’s usual optimisation passes on a larger-than-usual domain.
Full LTO
Imagine merging every compilation unit into one massive block of LLVM bitcode, then passing it through the middle-end a second time. A naive implementation, sure, but by some standards, also the best. This is called full LTO, and I tend to think of it as the purist approach to link-time optimisation.
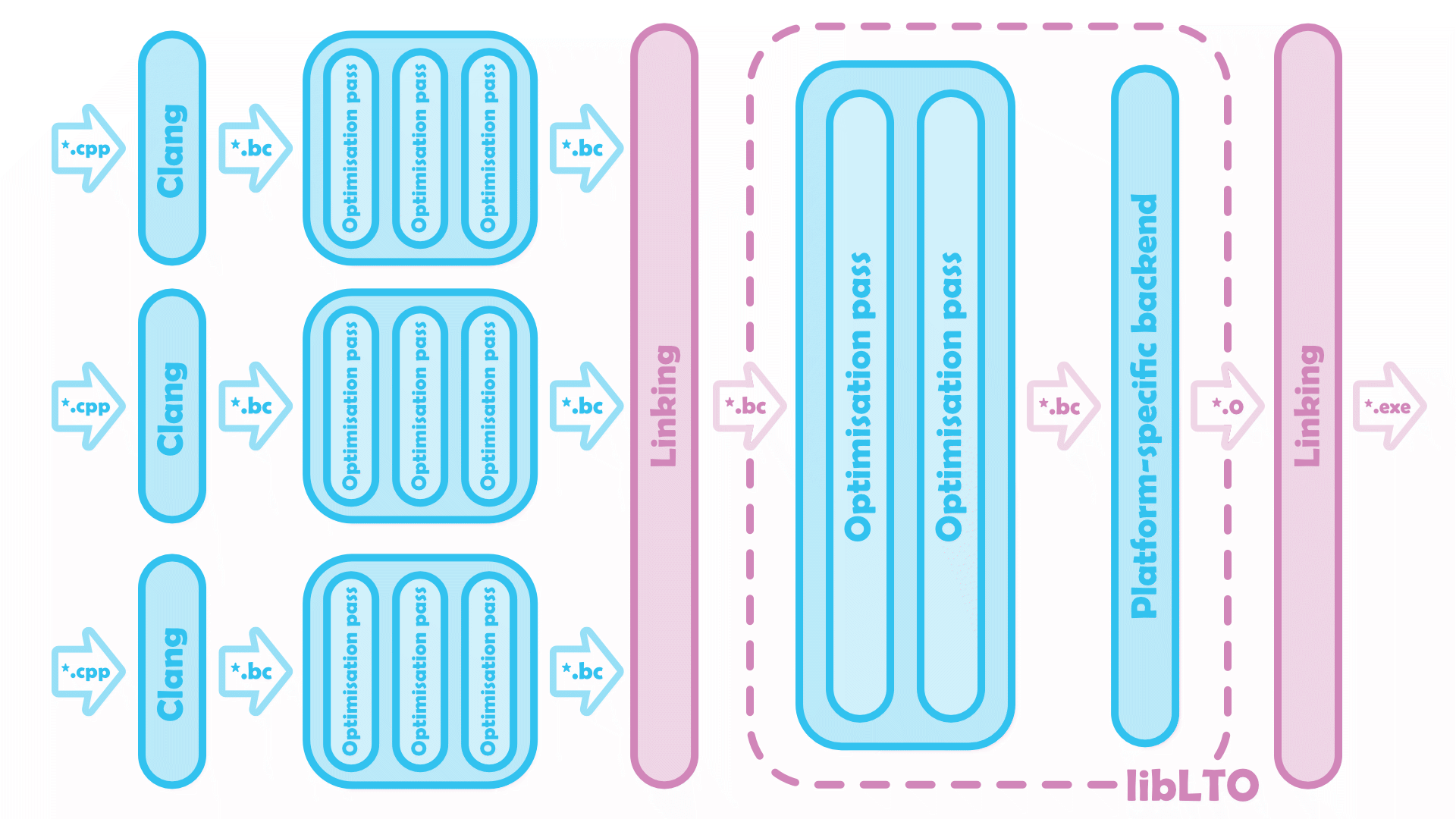 Full LTO resolves symbols twice, once as it links sources into a monolithic unit of LLVM bitcode, then again after libLTO has optimised and lowered it to machine code.
Full LTO resolves symbols twice, once as it links sources into a monolithic unit of LLVM bitcode, then again after libLTO has optimised and lowered it to machine code.
Targeting Linux with lld-link, we’ll build our sources as
1
2
3
clang foobar.cpp -c -O2 -flto
clang main.cpp -c -O2 -flto
clang foobar.o main.o -flto -Wl,-plugin-opt=save-temps -Wl,-plugin-opt=-print-changed -o main 2> main.passes.ll
This returns a snapshot of the main.bc IR at every steps of the full LTO process. The first of these, main.preopt.bc shows us the IR for the two files when they’ve just been merged. Disassembling with llvm-dis main.preopt.bc -o main.preopt.ll confirms bar is stripped, but little else.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@i = internal global i1 false,
@s = private unnamed_addr constant [13 x i8] c"Hello world!\00"
define i32 @main() {
%1 = tail call i32 @foo()
ret i32 %1
}
define i32 @foo() {
%1 = load i1, ptr @i
br i1 %1, label %qux, label %add42
qux:
tail call void @_Z3bazv()
br label %add42
add42:
%2 = phi i32 [ 42, %0 ], [ 52, %qux ]
ret i32 %2
}
define void @baz() {
%1 = tail call i32 (ptr, ...) @printf(ptr @.s)
ret void
}
Reading the IR dumps printed to main.passes.ll after each LLVM pass, we can verify that LTO applies:
- Interprocedural Sparse Conditional Constant Propagation to determine
mainreturns42as expected, - Global Variable Optimisation to strip unused globals (
@baz,@s) - Dead Argument Elimination to simplify
foo, by making it return avoidtype, and - Inlining to further simplify
foo- by removing it altogether!
This produces a wholly predictable result:
1
2
3
define i32 @main() {
ret i32 42
}
Full LTO is the pure form of LTO, but it isn’t always feasible. What we’ve seen above is, after that first pass through the linker, libLTO has to run (some subset of) LLVM’s usual optimisation passes on the monolithic module we’ve merged our IRs into - all on a single thread. At best impractical, at worst unusable, these extra optimisations will slow your link times to a crawl (and that’s assuming so large a main.bc will even fit in memory). Surely, surely, there’s a compromise to be found between performance and quality-of-life?
Clang flags -flto[=full]
Thin LTO
The funny thing Teresa Johnson and Xinliang David Li noticed about LTO is, there’s not all that many symbols libLTO really cares about at link time. Thin LTO generates a compact summary of each compilation unit, which can be “thinly linked” much faster than the full object files. During the thin link, the summaries are joined together as a global index with which we can quickly perform further, global, analyses - and function importing.
Using the thinly-linked index, each unit imports only those functions that will (likely) be inlined, and excludes those that would (likely) be ignored. It is this approximation of full LTO that allows us to parallelise the link-time optimisation step. Rather than passing a single, monolithic *.bc to libLTO, thin LTO can optimise the extended compilation units concurrently and then continue through the backend as usual.
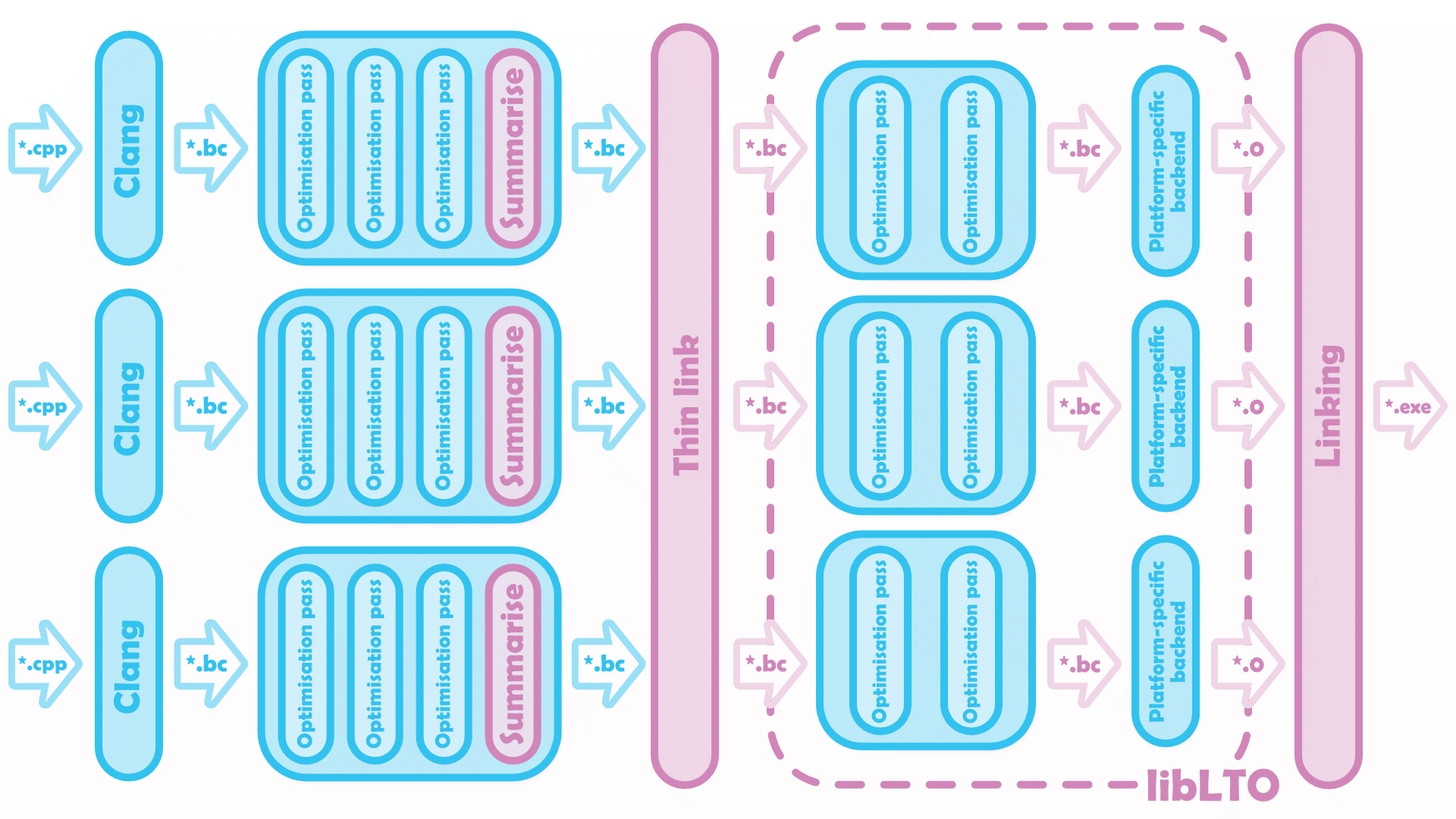 Thin LTO removes the bottleneck introduced by libLTO. Much like a traditional build pipeline - and unlike full LTO - only the link step(s) are single-threaded.
Thin LTO removes the bottleneck introduced by libLTO. Much like a traditional build pipeline - and unlike full LTO - only the link step(s) are single-threaded.
Clang flags -flto=thin
LTO, But Better (Better Build Times, Anyway)
In terms of raw performance, thin LTO is a negligible downgrade: using it to build Clang 3.9, Stinnett finds a speed-up of 2.63% versus full LTO’s 2.86%. The trade-off for that extra 0.23%, however, is compiling and linking with full LTO takes him 4x longer! As benchmarks go, it paints an instructive picture of what ‘better’ LTO looks like.
With my last post, I wanted to highlight various cheat codes for PGO, and get in to how, when, and why they complement each other. This time around, I’m working backwards. Full LTO is, by definition, the most performant LTO can get: if you want to eke out improvements across sources, you won’t do better than optimising every compilation unit with complete knowledge of every other compilation unit.2 Its variants are instead designed to reduce build times without shifting (too much) sluggishness onto the end user. Depending on your project, parallelising with thin LTO might not be the only way of bettering your quality-of-life as a developer - but to temper your expectations, because while none of the following tricks should meaningfully worsen run-time performance versus full LTO, they’re not going to make it faster either.
2 In theory. In practice, LLVM puts artificial limits on how aggressive that optimisation pipeline can be, otherwise monolithic modules on larger projects become too resource-intensive to process. Being more scalable, thin LTO forgoes this restriction, which does occasionally translate to better runtime performance. Always be profiling!
Linker Caching
Clang is an incremental compiler, in that it only recompiles sources that have been changed since the last build. Unfortunately, because full LTO merges all of its compilation units into one before link-time optimisation, whenever any of those sources are edited the entire libLTO step will need rerun. Thin LTO on the other hand can cache and reuse earlier work such that, much like everything other than the link steps can run in parallel, everything other than its link steps can run incrementally.
Recalling the thin LTO pipeline, we can see that a source’s dependencies are itself and the sources it imports from (plus a couple more auxiliaries detailed by Johnson). If none of these change, then that source’s link-time optimisations needn’t be deprecated and rebuilt before the final link step. To enable incremental thin LTO, you’ll need to manually provide your linker of choice with a path relative to the build directory wherein it can cache the fully optimised bitcode. Further flags for “pruning” the cache size are also available.
ld.lld flags -Wl,--thinlto-cache-dir=<path/to/.cache>
ld64.lld flags -Wl,-cache_path_lto,<path/to/.cache>
lld-link flags /lldltocache:<path/to/.cache>
Unified LTO
Despite the shared file format, full and thin LTO produce subtly different bitcode, their structures deliberately made incompatible to avoid confusion. Unified LTO lifts that incompatibility. If we can guarantee both modes of LTO will generate the same binaries at compile time, with whatever extra summary information squared away “on the side”, it becomes possible to toggle between the two without need for a clean build. The linker has to be rerun, of course, but the sources themselves don’t need recompiled.
Unifying the bitcode structure means the decision of which mode of LTO to use can be left until link time. As discussed, thin LTO builds faster, but full LTO will be needed to unlock peak runtime performance. Deferring that decision between the two is therefore very useful, as it allows us to run production builds with full LTO without nuking our existing build directory (a trick that also comes in handy for profiling the two modes side-by-side).
It would take a bit of trial and error to verify this result myself. The flags involved are a little finicky, you see, and none of my reading had turned up an example of how to use them without triggering a rebuild on accident. LLVM warns you that -funified-lto by itself will go unused during compilation, but you can’t set -flto=full or -flto=thin at compile-time either. Instead, pass -funified-lto -flto (without an argument) to the compiler and specify -funified-lto -flto=[full/thin] in the linker flags as below:
1
2
3
clang foobar.cpp -c -O2 -funified-lto -flto
clang main.cpp -c -O2 -funified-lto -flto
clang foobar.o main.o -funified-lto -flto=full -o main
The other benefit of unified LTO is it allows building with a mixture of LTOs. Using thin LTO to cut corners on internal tools, unit tests, etc., but not the project’s performance-critical core, might well be viable… provided the project has enough auxiliaries that they’re already slowing link times.
Clang flags -funified-lto
Fat LTO
Let’s take that concept of deferring to link-time one step further - what about deferring the very question of whether to use LTO altogether? Recall that a traditional build process passes native object files, not bitcode, on to the linker. If it sounds inconvenient to resolve the two formats, that’ll be because it is. Fat LTO can only cut this Gordian knot by building both, a brute-force solution to the problem at hand.
The motivations for and benefits of this new method are, as far as I can tell, the same as unified LTO, so I won’t belabour those here. They complement each other - fat LTO affords flexibility on when and where we optimise at link-time, unified LTO the orthogonal choice of how we’ll optimise it - but it’s also important to mark the differences. Fat LTO objects are, well, fat. Unifying LTO is a matter of lifting artificial constraints on the structure of LLVM bitcode, but fat LTO objects store two equivalent forms of the same underlying binaries. This comes at a cost to storage, and to build times (optimisations done to *.os get thrown away), so where I’d recommend enabling unified LTO by default, it isn’t worth using the following flag if you have the choice:
Clang flags -ffat-lto-objects
Distributed Thin LTO (DTLTO)
Extremely large projects often demand distributed builds across whole networks of machines, with each agent being delegated its own independent work. Full LTO, being single-threaded, also needs run on one single instance of libLTO, but thin LTO slots into a distributed system nicely…
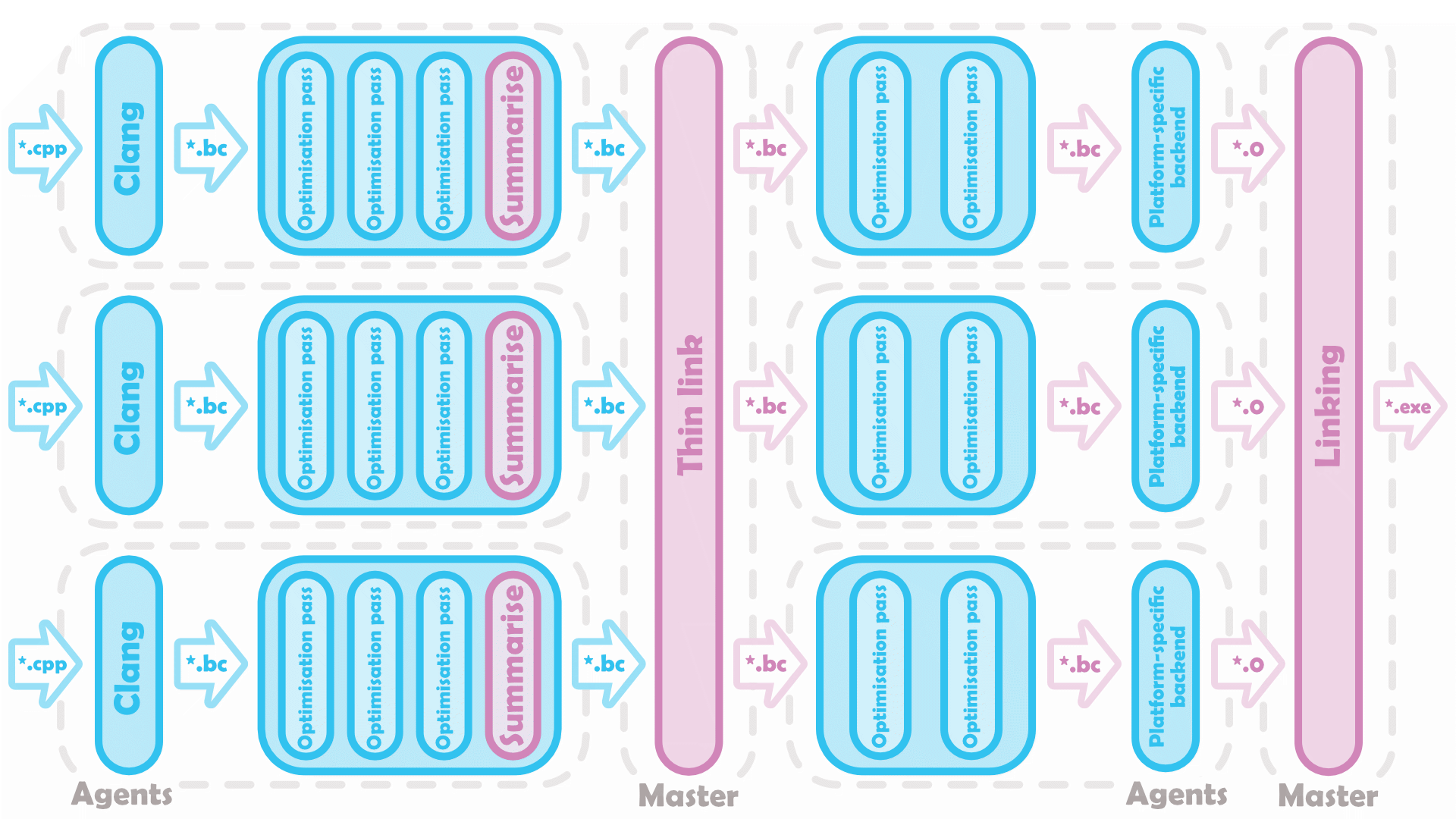 Distributed Thin LTO has a master device coordinating optimisations to separate sources by separate agents. The master also handles those linking steps that can’t be delegated.
Distributed Thin LTO has a master device coordinating optimisations to separate sources by separate agents. The master also handles those linking steps that can’t be delegated.
I’ll leave the particulars of configuring a distributed system to the build engineers. At the abstract level, all that’s happened is LLVM has separated out its -flto=thin flag for different stages to run on different machines. LLVM exposes -thinlto-index-only to run its thin link on the master, then -fthinlto-index for agents to optimise based on that thin link (and clearly the final linking step won’t need any more flags than usual). Distributed thin LTO (DTLTO) can further be incrementalised, but again - this is an intentional consequence of thin LTO’s design, there’s not really anything new to get in to here.
Clang flags -fthinlto-index=<path/to/*.thinlto.bc>
ld.lld flags -Wl,-plugin-opt,-thinlto-index-only
lld-link flags /thinlto-index-only
Unsupported by ld64.lld.
LTO && PGO
All told, the most intuitive definition of LTO I can think of is optimisation with knowledge of all sources. If you’d asked me the same question on my last post, I’d probably have described PGO as something like optimisation with knowledge of how a source is used. These are orthogonal properties, you can absolutely have either one without the other. And that, I think, gets us back to where we started.
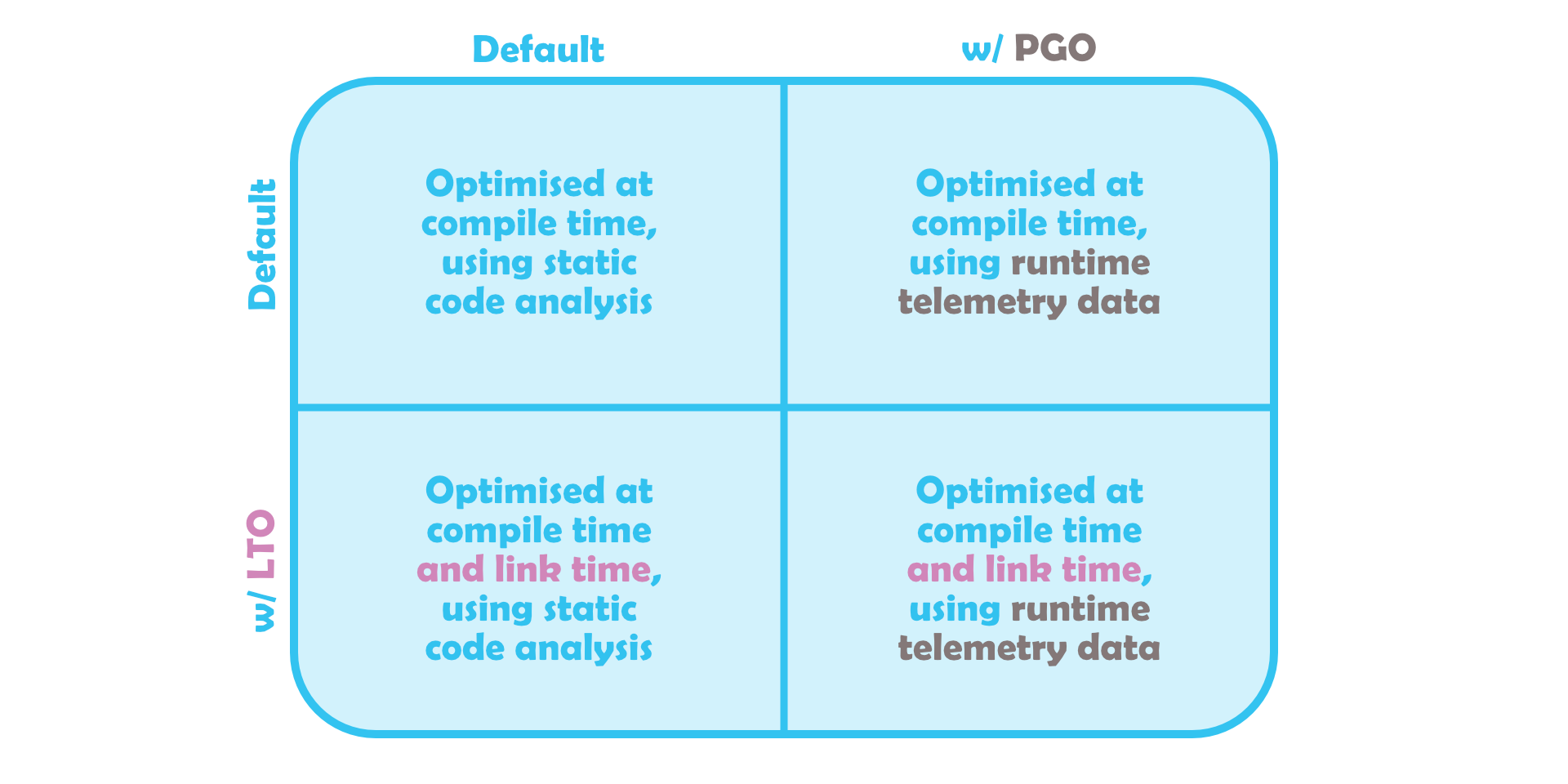 Just LTO with extra profiling data, right? LTO is admittedly treated as a prerequisite for PGO by MSVC, but that’s a
Just LTO with extra profiling data, right? LTO is admittedly treated as a prerequisite for PGO by MSVC, but that’s a fucking stupid quirk of how the compiler is written. Rest assured that Clang and GCC both support either/or, and the two techniques remain conceptually distinct.
My recommendation would be to enable LTO on your games from day one: thin, incremental, unified LTO locally, full LTO for production. Unlike PGO, which requires a steady flow of .profraw telemetry data to base its optimisations on, once LTO is up and running it’s a safe bet you’ll never worry about it again. Honestly, it makes sense that someone could form this fuzzy sort of misconception that PGO directly builds on LTO, since it rarely makes sense to enable them the other way around. As referenced last time around, profiles captured with different -flto flags will reliably have zero overlap,
But what about pre-existing projects? Porting games from 10, 15, 20 years ago, I’m very often working with legacy code written before link-time optimisations were even conceived of. If that code takes a shortcut and exploits some undefined behaviour - it’s a safe bet that LTO is gonna brick it. Me personally, I’m still an advocate for sucking it up, enabling the flags, and slogging through the ensuing regressions one by one, but I can’t rule out that that would introduce some subtle bugs into the mix. If you’re coming in to a new codebase, maybe the more measured approach would be to turn on LTO only after UBSan-itising…
None of this is to say that LTO, or PGO, is inherently dangerous or inherently unknowable. On the contrary, if there’s one point I want to make here, it’s that LTO, PGO, and the LLVM middle-end are homoousios; of the same stuff. That colleague of mine puts it best:
My mistake was imagining the optimisation steps in LTO is distinct from normal compiler optimisation.
The stated aim of the introduction I wrote - christ, four months ago? - was demonstrating that result, but on reflection this is just as much about the act of demonstrating results. Working in cross-platform development, I can’t take for granted that a flag I’ve added on Android will behave the same on iOS, or Switch, or when I build with xcconfig rather CMake. Being able to get under the hood and see down what the compiler’s doing, optimisation pass by optimisation pass, that’s what’s going to convince me (not to mention my project leads) all this tinkering is safe. LTO is a useful cheat code, but learning LLVM IR is how you git gud.